
Deja vu — How Server Components Are Changing The Game Using Old Ideas
A brief look at the history of web rendering, what problems different strategies were trying to solve, and how Server Components conceptually fit into all of this.
This is the write-up of a talk I gave at the ReactBris meetup (in a simplified form) and at Web Directions Summit 2023. You can find the original slides here.
Innovation
What is innovation, and what powers it?
I think about this meme a lot. A news article on how wind-powered cargo shops are going to revolutionise the shipping industry.
And in good old internet fashion, social media took this article and tore it to pieces. With comments like “Wind powered ships, what a time to be alive”, “We really do live in the future”, and just generally making fun of the idea that something like wind-powered ships, which in their collective mind was just the re-invention of sailboats, which we’ve had for thousands of years, could be deemed innovative or groundbreaking.
I think about this a lot cause it’s how I sometimes feel being a Software Engineer, especially in the frontend community and ecosystems. How often do we see people come in with new ideas, and we put them aside, or even worse, laugh them off, just because we think they’re just old ideas dressed up?
In the following, I’ll try to explain how Server Components conceptually work, why we need them and hopefully show that innovation is often driven by applying old ideas and principles to new technologies to improve them.
To do all of that, I think we need to take a brief look at the history of web rendering, the different strategies we’ve applied over the past 15 or so years, what problems they solved and how we got to where we are today.
Good ol’ HTML and CSS
And what better place to start than the late 90s — early 2000s? When we were writing plain HTML and CSS, for the most part. Those were simpler times when it came to development itself, but also when it came to how we rendered websites.
Disclaimer: I am going to over-simplify a few things here and throughout this article to be able to get my main points across and not get too hung up on irrelevant details.
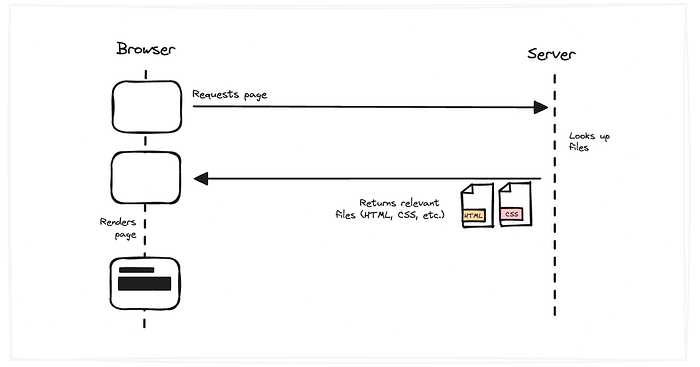
- Back in the day, the browser would request a page from the server
- The server would look up the relevant files from the file system and return them
- And the browser would then use the files to render the page
Again, simple. And this was great from a user experience perspective. Pages would render fast because there’s not much going on on the server; it just needs to look up files, and there’s not much going on on the client either; it just renders the page. Very little back and forth, no extra logic needing to be executed, and no other shenanigans happening.
But there are some very obvious downsides to this approach from a developer experience perspective.
Building large-scale websites and applications was a pain because it meant you had to write a lot of code. Even worse, a lot of redundant code due to the lack of abstractions helping with reusable functionality, layouts and components.
Building dynamic applications was pretty much impossible. There was no way to use data from external sources like databases, and you couldn’t really serve content that was specific to the user who requested the page.
Moving to the server
So, we started using server-side languages like PHP. This is the era of Wordpress, Drupal, Magento and the sorts, so we’re still talking early 2000s.
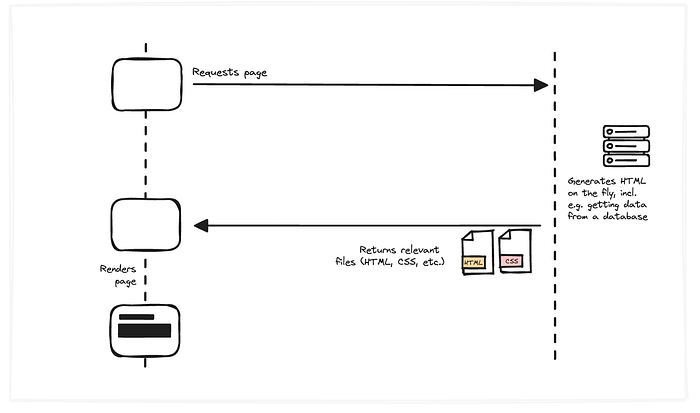
With server-side languages, when the browser requested a page, the server would actually do things. There’s actual logic happening, including potentially pulling content from databases, etc.
Then, the server would generate the HTML on demand and would return files just as it did before. So, for the browser, nothing really changed; it would still just use the returned files and render the page.
This fixes all of our DX problems; now, we can easily write abstractions for reusable logic, write templates for layouts and components, and generally break down large applications in nice little chunks. We can also easily write dynamic applications with all the power we have in whatever language we choose on the server.
But we took a step back from a user experience perspective. Now that the server actually does things, the response times get a lot slower. And this gets worse the more logic the server needs to run and the more complex the application is. Meaning: it doesn’t scale well.
And this becomes very apparent when the user navigates.
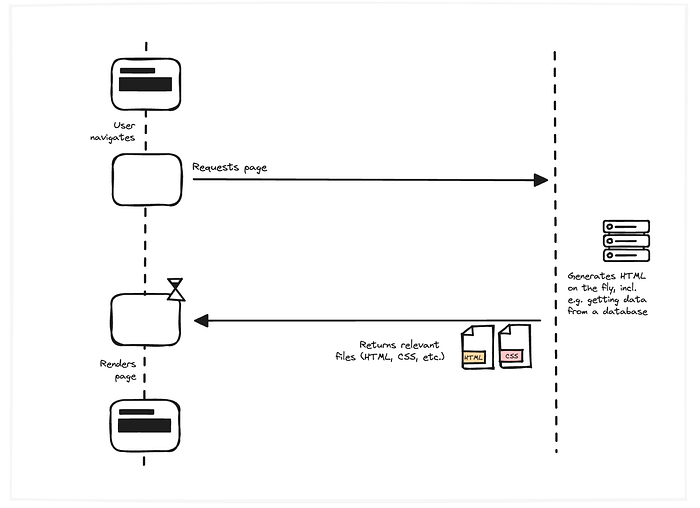
The page goes blank, as is the browser default behaviour, while we’re waiting for the server response of the new page. The longer that takes, the worse the experience for the user at the other end.
What can we do about that?
Introducing Javascript and AJAX
Let’s introduce Javascript, arguably the main protagonist (or antagonist, depending on what side you’re standing on) of the web for the last decade or two. As well as its smaller side-kick “AJAX”.
AJAX stands for “Asynchronous Javascript and XML” and was invented by Google in 2005 to make it possible for websites to request data from the server, even after they’ve already been rendered. All through the magic of Javascript 🧙
But what does that mean for our rendering process?
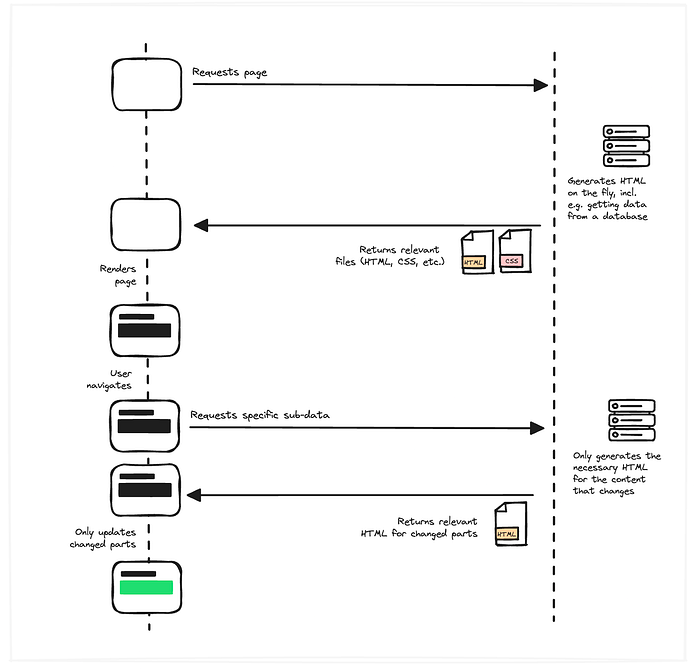
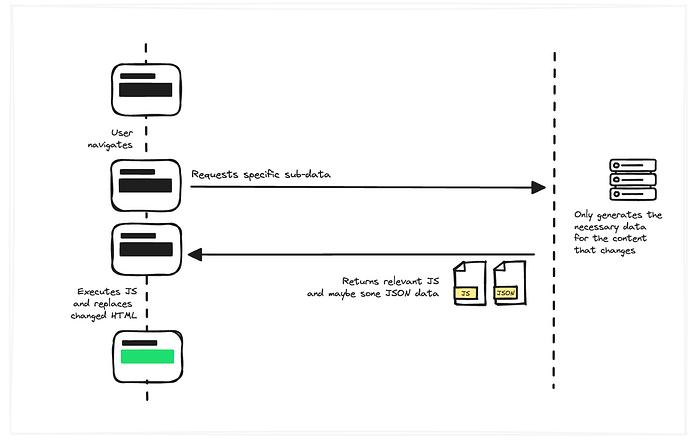
The initial render doesn’t change (for the time being), but now when the user navigates, we intercept. And then we’re in full control.
We’re in full control over what we show to the user while we’re waiting for the server response, e.g. displaying nice loading states and progress bars, and we’re also in full control over what we request from the server. We can say: hey, we already have the layout; all we really need from the server is the new content of the main section of the page.
This means we can reduce the amount of work the server needs to do, we can reduce the amount of data the server needs to send back over the network, and then we’re also in full control over what we want to do with that response. Instead of having to replace the whole DOM, we can be more specific and only replace the elements we know have changed.
Awesome, right? This massively improves the user experience when navigating through the app. It reduces actual load times by reducing the amount of logic required on the server, but it also improves the perceived performance by allowing us to give the users visual feedback while stuff is loading.
But, once again, we actually took a few steps back from a developer experience standpoint. And I hope you start seeing a pattern here: the evolution of web rendering is essentially just a continuous game of tug and pull, where we are trying to find the balance between UX and DX trade-offs.
In this case, the developer experience isn’t great because the code is still split into two parts, often across two separate code bases. One is the server-side code, e.g. written in PHP, that’s responsible for generating the HTML on demand. This isn’t great to start with, but now it gets a lot messier really quickly since we start dealing with subsets and small chunks of HTML or other response formats on the server while also starting to add DOM manipulations dealing with HTML in our Javascript on the client.
Personally, I also think that AJAX was just a little bit ahead of its time. We’ve had jQuery, introduced by John Resig in 2006, which helped with the general adoption of Javascript across the web and made using AJAX a lot easier (especially when it came to cross-browser quirks), but actual MVC frameworks that would help us build complex, large scale web applications were still rare. This meant, more often than not (and I’m as guilty as anyone else of that, maybe even more), we would write our own custom solutions to many of the common problems at the time.
And this is why, unfortunately, even now, when we think back to this era, we still think about spaghetti code — cause that’s what we wrote.
Client-side rendering and SPAs
To address that, what if we moved more stuff to the client? What if we moved everything to the client?
This will likely start to look more and more familiar now, as we’re entering the era of client-side rendering (CSR) and single page applications (SPAs), with frameworks like KnockoutJS and Angular in 2010, and then later React and Vue in 2013 and 2014 respectively.
And the idea is simple: when the browser requested a page, the server would basically go back to square one and just look up static files from the file system. However, the HTML is now just an empty shell (e.g. an empty div) and some Javascript that now has the sole responsibility for generating the HTML.
So when the browser renders the HTML, the page is still empty (again, the HTML is just an empty shell at this stage). It then parses the Javascript, which means it might stumble across a few more resources it needs, like other Javascript files or images. It then parses those and might stumble across some data requests it needs to send to the server, which then needs to do a bunch of work to return that data, which gets parsed …. and so on.
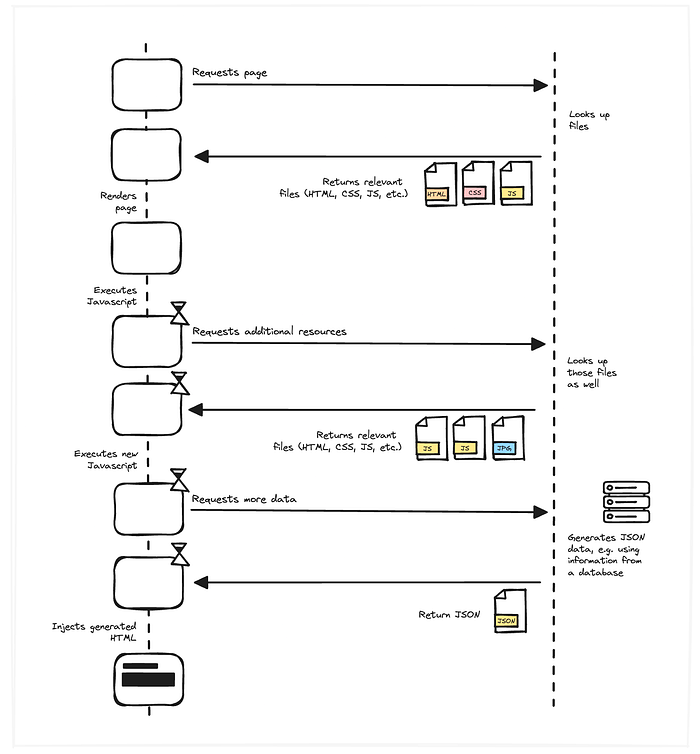
I hope you can tell: this initial render is just awful from a user experience standpoint. It’s leading to what we call a “network waterfall”, which means there’s potentially a lot of forth and back happening between client and server while the client parses and executes the Javascript, which all happens sequentially cause the browser doesn’t know about it until the Javascript is being executed. This cascade of network requests gets worse the bigger and more complex the application is. Again, this doesn’t scale well.
However, once the initial render is done, we get all the benefits of the previous AJAX approach. We’re in full control to show loading states, we only request from the server what we need, and we only replace the content that has changed.
We also obviously improved the developer experience massively this time. Frameworks like React revolutionised how we build web apps, made building complex interfaces more accessible to a lot of developers, and — I believe — just in general further drove the adoption of the web as the medium of choice for a lot of product teams.
But what can we do about that initial render?
Static site generation and server-side rendering
This is where we see a lot more people taking a few steps back, looking at some of the old strategies we’ve used in the past and attempting to apply the good ideas from those to the new technologies we introduced in the meantime.
Static site generation (SSG)
The initial wave was “static site generation”. What if we kept using those awesome new frameworks like React and Vue to write websites and apps but then generated static HTML from that at build time? This could either happen locally or, more likely, through some form of CI/CD setup whenever the content changes.
What started with experimental packages and webpack plugins eventually led to the introduction of proper frameworks like Gatsby and NextJS.
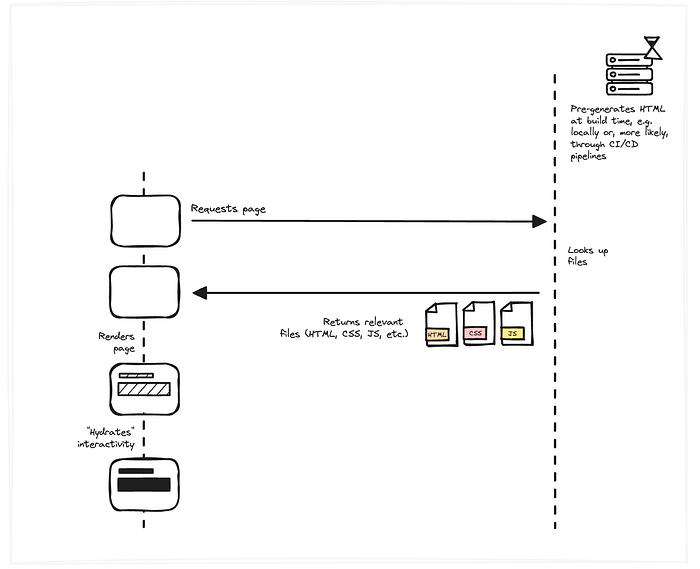
This is great from a user experience perspective. We’re basically back to the plain HTML days:
- The browser requests a page
- The server is back to only having to look up the static files we pre-generated and return them
- And the browser uses them to render the page
- But now, we introduce a new step! This is necessary because we’re writing the core code in Javascript, so it likely contains a lot of client-side logic like state, effects, context, event listeners, etc, which can’t be included in the static HTML we generated. So, to make sure we get all of this interactive stuff, we need to execute the JS and inject it into the page. This is what we call “hydration”.
We cherry-picked all of the good parts of static HTML while keeping all of the benefits of SPAs when the user navigates. The framework will intercept, only fetch what it needs for the new page, and then replace all changed parts of the website for us. Nice!
But this approach obviously has the same shortcomings we had back in the HTML days: it doesn’t really work well for dynamic content.
Server-side rendering
But the solution to that is pretty straightforward; we’ve done it before when we transitioned from plain HTML to PHP, generating HTML on demand.
However, instead of PHP, we now use Node. It’s the same we’re doing for static-site generation, running our JS in Node to generate the HTML, but instead of doing it at build time, we do it on demand on a server.
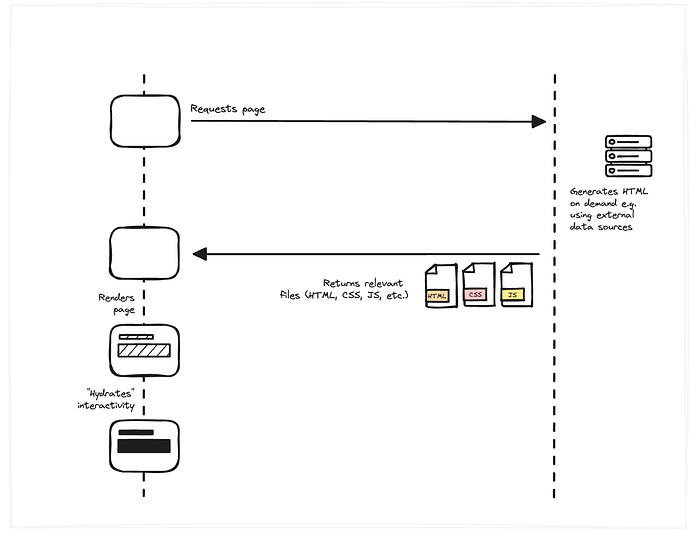
We’re basically back in the AJAX days: the server generates HTML on demand, and when we navigate, we use the power of the client-side rendering to create a smooth experience for the user. We do still have that “hydration” step, meaning on the initial render, the content is there but not interactive yet until that step has been completed.
But, generally speaking, we finally came full circle: we’ve brought the code close together, having everything in JS now, and we’ve introduced frameworks to help us with common abstractions and “best practices”.
And we’ve introduced a lot of them! While it might feel like NextJS has the upper hand in this game, I think there’s a lot of healthy competition in this space, with frameworks like Gatsby, Remix, FreshJS, etc.
Server Components
This is where we’re finally getting to Server Components. React first introduced the concept in 2020 when Dan Abramov and Lauren Tan showcased it during a conference talk.
Since then, the feature has pretty much been experimental. But we have seen it getting introduced into the wider ecosystem more and more, most recently through Next 13, where the new app router is built on top of Server Components.
It’s important to note that Server Components are not a new rendering strategy. It is not replacing SSR or SSG; instead, think of it as an enhancement to both of those.
But what problem are they trying to solve?
The “hydration” problem
There are a few things Server Components are aiming to do, but there are two primary goals relevant to us in this context: tackle the “hydration” bottleneck we’ve just seen in the SSG and SSR flow and, in the process, reduce the size of our client-side JS bundles.
But where does this “hydration” problem come from? We didn’t have it back in the PHP and AJAX days, right?
Fundamentally, I think the core of the issue was introduced when we moved to client-side rendering and SPAs. All the frameworks created at that time (React, Vue, etc.) were created to be run on the client, allowing developers to easily handle things like event listeners, local state, side effects when the page or individual components re-render, etc. And that’s great from a UX perspective; we want websites and apps to be more interactive; we want to create more immersive experiences.
But it didn’t translate when we moved back to the server. HTML itself doesn’t have any concept of all of these interactive things. So when we render HTML from our JS on the server, they get lost. To ensure the website still does what we want it to do, we then added that “hydration” step.
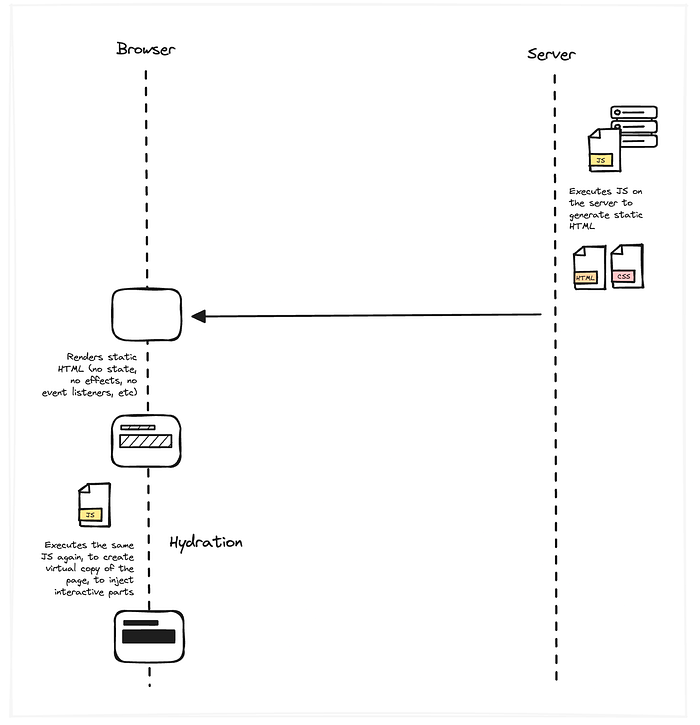
Very simplified, that hydration step basically re-runs all the JS we already executed to pre-render the page (either statically or on the server) to create a virtual copy of the same page. It then uses that virtual copy to inject all of the interactive parts into the rendered DOM.
But that’s slow, especially the larger and more complex the application gets. Which means, you guessed it, it doesn’t scale very well.
And if you think about it, this is the complete opposite of what we did with PHP and AJAX, right? When we were generating HTML through PHP, it would be static. There is no way to describe dynamic behaviour, like local state, effects, etc, in PHP. Instead, we would create a separate Javascript file, which will target specific elements on the page to make those elements interactive.
So we basically went from a “static first” mindset, only injecting interactivity where specifically needed, to “everything is or can be interactive”.
The problem with all of this is that the bundler has no idea whether certain code or components are interactive or not. So, for sites that use classical SSR or SSG, we need to hydrate the whole page. Meaning, as I mentioned before, re-running all of the Javascript we already ran on the server, generating the HTML, creating a virtual copy of the DOM of the page, and then injecting the interactive parts into the existing DOM.
Hydration strategies of the future
Server components are trying to take a step back and re-apply more of the old mindset. What if we allowed developers to tell the bundler whether a component is static or interactive? Or, in other words, whether a component can be fully rendered on the server or if it needs to be hydrated on the client. And what if we made everything static by default (like back in the PHP days) but made it easy to opt out and make components interactive?
That’s all the “use client” directive React introduced really is. A hint for the bundler that this component needs to be hydrated and, therefore, that its code needs to be included in the client-side bundle.
On the flip side, it also tells the bundler which components are meant to be static. By definition, those components only ever need to be rendered once on the server, so they don’t need to be hydrated, and their code can be completely excluded from the client bundle.
This is huge! It means, for a lot of static content, we can completely ignore all the dependencies we might need (like date formatting, markdown to HTML conversion or syntax highlighting, e.g. if you’re showing code snippets on your website) that used to blow up our Javascript bundles. So we’re reducing our bundle sizes, which improves the overall load time to start with, but we also reduce the amount of code that needs to be executed for the hydration step, which further improves the time until the page becomes interactive.
This is what’s called “partial hydration”, and React is by no means the only library to look into this or even the front runner. Frameworks like Astro, which introduced the idea of “component islands” in 2019, are trying to achieve very similar things: allowing developers to write code that’s static by default but then letting them opt out of the static behaviour and add interactive elements where needed.
Other frameworks go even further with what they call “zero hydration”. Qwik, created by Misko Hevery, who also created Angular, is probably the most popular one at the moment. The idea is that there is no hydration step at all on the initial render. Qwik achieves this primarily through two things:
- Resumable state — the server can leave state in serialised form within the HTML, so it can be picked up and “resumed” at any later point without having to start from scratch again
- Going hard on the code splitting — this one is probably more relevant in the context of this article; in Qwik, everything is split into its own tiny little chunks, every function, every closure. Then, instead of hydrating dynamic parts and logic into the DOM at the initial load, Qwik waits until the user interacts with the elements that need those dynamic parts. For example, say we have a button with a click handler on it; the JS code for that click handler is a tiny chunk, and that chunk only gets loaded when the user actually interacts with that button.
There’s obviously a balance to find with these approaches, but I think it’s interesting to compare them and their philosophies. Essentially, when we do full or even partial hydration, we’re still wasting a lot of resources and time hydrating elements that the user will never actually interact with.
Other benefits of Server Components
I don’t really want to go into too much detail here since the article is already long enough as it is, but I think it’s worth mentioning some of the other benefits of server components so you can dig deeper yourselves if you find any of these interesting or intriguing:
- Since SCs are only ever rendered on the server, they can make dealing with server-side logic much simpler, e.g. getting data from the database
- Since SCs can be asynchronous functions, the React team made sure they work really well with Suspense. The server-side rendered SCs are actually sent to the client in a JSON-like format that describes the components in a way that React can then turn into HTML. That format can also mark components as “suspended” and trigger any boundaries to show, for example, some form of loading state. The format can also easily be streamed so that when the server finally resolves the asynchronous function, React can simply swap out the loading state with the (now available) component 🤯
Conclusion
The point of this article was primarily to give some context on why Server Components exist, what problem they are trying to solve and how all of this fits into the (ongoing) evolution of rendering on the web.
But if you are looking for some personal takeaways, here are a few:
Do I think, conceptually, Server Components are the future? Yes, 100%. They very specifically solve a problem we’ve introduced when we moved to client-side rendering and SPAs and then tried to move back to the server. Fundamentally, I think Server Components will help us as developers to get back into that “static first” mindset I’ve mentioned, and enforce best practices. A lot of the anti-patterns we’ve started adopting, e.g. using useState and useEffect everywhere, even when it’s not needed, can be addressed through that mindset shift. Server Components also encourage using the platform more, which by now has become a bit of a meme, but I do think it’s important. If your server component can’t hold local state, use the platform (aka the URL and query parameters) to store the serialisable state. This automatically leads to a better user experience, cause state can now more easily be shared and persisted by your users — win-win.
Do I think the way Server Components are implemented in React and especially in Next is perfect? Absolutely not, and that’s fine. There’s a reason the feature went through that extensive “beta” phase. Personally, I think the developer experience can still be improved. There are still a lot of unintuitive parts that lead to confusion and misunderstandings in the community. But that’s okay; no one nails a new thing on the first try. And other libraries and frameworks like Astro and Qwik looking at the same problem from different angles will hopefully drive improvements, especially around the DX, to improve the whole ecosystem.
Do I think everyone needs to start using Server Components now? I’m only including this here, because I always see these articles and talks online that showcase a cool new trend or feature, and then tell people they have to use it or otherwise they are stupid. I think that’s pretty offensive to start with, but then also generally poor and useless advice. I don’t know your background, your context or the specific requirements your projects might have. If you’re mostly working on small apps and websites, where the hydration bottleneck is not really noticeable, and bundle size is not really an issue, the benefits of Server Components will likely be very minimal. However, what I do hope is that the concept eventually becomes so baked into our tools, patterns and best practices that in the future, you don’t really have to think about whether or not you need to use it.
